Torch 那些坑
Torch 用户经常会在使用 Torch 的时候遇到各种各样奇怪的坑,本文记录了作者遇到的部分常见或略微有些坑的坑,通过关键词和报错内容双重索引的方式在此简单分享。不过目前积累得并不多,就先按照出现频率划分。
0x01 关键词:inplace operation
报错内容:one of the variables needed for gradient computation has been modified by an inplace operation
可能出现在:
Tensor索引处
这里所指的 inplace operation 一般包括但不限于:
1 | data += noise # 使用 += operator |
在求导阶段中涉及的 Tensor,包括叶 Tensor,即标出 require_gradient=True 的 Tensor,不应当使用 inplace operation,而应当修正为:
1 | data = data + noise # 直接用新 Tensor 代替 |
类似的报错还有:Output 0 of UnbindBackward0 is a view and its base or another view of its base has been modified inplace. This view is the output of a function that returns multiple views. Such functions do not allow the output views to be modified inplace. You should replace the inplace operation by an out-of-place one.
这一问题特别容易在这种情况下出现(尽管这种写法一般要避免):
1 | for ind, img in enumerate(imgs): |
即使前面的 inplace 更新并不会对后面索引到的数据有影响,依旧会报错。
0x02 关键词:view size
可能出现在:
- 更新数据处
报错内容:view size is not compatible with input tensor's size and stride
在调用 Tensor.view()(参考 PyTorch Docs - view)时,可能会发上上面的 Runtime Error。这是 PyTorch 在内存/显存中存储 Tensor 的方式导致无法直接调用该函数。
可能的解决方案
对涉案 Tensor 先调用 contiguous(),再调用 view(),例如:data.contiguous().view(batch_size, code_length)
0x03 关键词:PriorityQueue, ambiguous value
报错内容:Boolean value of Tensor with more than one value is ambiguous in Pytorch
可能出现在:
- 搜索
网上很多 Blog 里写这个问题会在实例化和使用 NN 的 Module 的时候出错,但若想用 PyTorch 写 A* 什么的(虽然这听起来很扯,但我确实这么干了),在往 PriorityQueue 里 put(priority, tensor) 的时候,或在基于 heap 实现的存储结构并调用 heappush() 等函数时也会报这个错。
问题出在 heap 不能很好地处理作为队列项的 Tensor。一种可行的解决方案是重载 PriorityQueue.put() 对应的底层方法,但这个显然不是面向大多数人的解。
可能的解决方案(奇技淫巧)
开个 list 或找个大 Tensor 存储涉案 Tensor,然后在 PriorityQueue 里 put(priority, index)。当然作者还没评估这个方法的性能损失。
0x04 关键词:Open3d Python instance C++ type
报错内容:Unable to cast Python instance to C++ type (compile in debug mode for details)
可能出现在:
Open3D库- 调用
Vector3dVector()等将点云转换为Open3D的内置数据类型时
- 调用
虽然这个报错让人以为是底层库出了问题,但其实只是 Open3D 的报错。
可能的解决方案
检查调用时传入的 Ndarray,确保它是一组点云,且形状为 (-1, 3),即为 $N_{\text{points}}\times 3$。
0x05 关键词:batched 矩阵运算
这个问题经常出现在 3D tasks 中,可能只是因为个人喜欢用 torch.bmm 导致的,也许会有更简单的 API,欢迎在博客下方多多指教。
考虑下面的运算场景:
- 参考系 $A$ 下一批点的坐标
points形状为batch_size x num_points x 3 - $A$ 相对于 world coordinate 的 global translation
translations形状为batch_size x 3 - $A$ 相对于 world coordinate 的 global rotation matrices
rotations形状为batch_size x 3 x 3
值得注意的是,这一批点的 global translation 与 rotation 是统一的。
此时需要计算在 world coordinate 下点的位置。一种常见的做法是为 points 左乘 rotation matrices,然后加上 translation。由于点是以 batch 形式出现,一般需要:
- 将 points flatten 成一个大 batch:
-1 x 3 - 将 translation 和 rotation 都 tile 成和上面 flattened 的 points 一一对应的形状:
-1 x 3 x 3或-1 x 3 - 使用
torch.bmm运算 - 将结果变回原来的形状(与原
points一致)
因此,很多人会这么写(考虑出现非 contiguous 的情况,使用 reshape ;有些时候可以用 view):
1 | shape = points.shape |
然而,这么计算的结果是错误的,原因是在对 rotations 和 translation 进行这样的 tile 操作时,实际上是将各个 batch 的数据沿着 batch 的维度重复。
举个例子,以 batch_size = 2 的 4 个 batch 为例:一开始,rotations 和 translations 的第一维度均如下
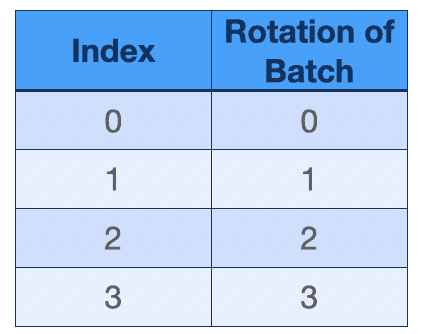
将它 tile 完后:
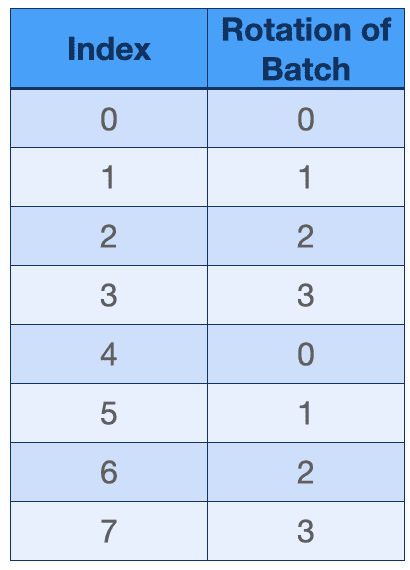
但按照同样的道理,将 points 沿着 batch 维度 flatten:
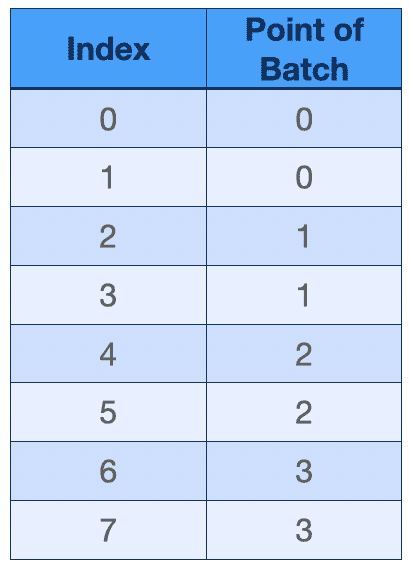
把他们放在一起比较,问题就显而易见了:尽管三个 Tensor 都变成了可运算的形状,但内部的对应关系并不一致。
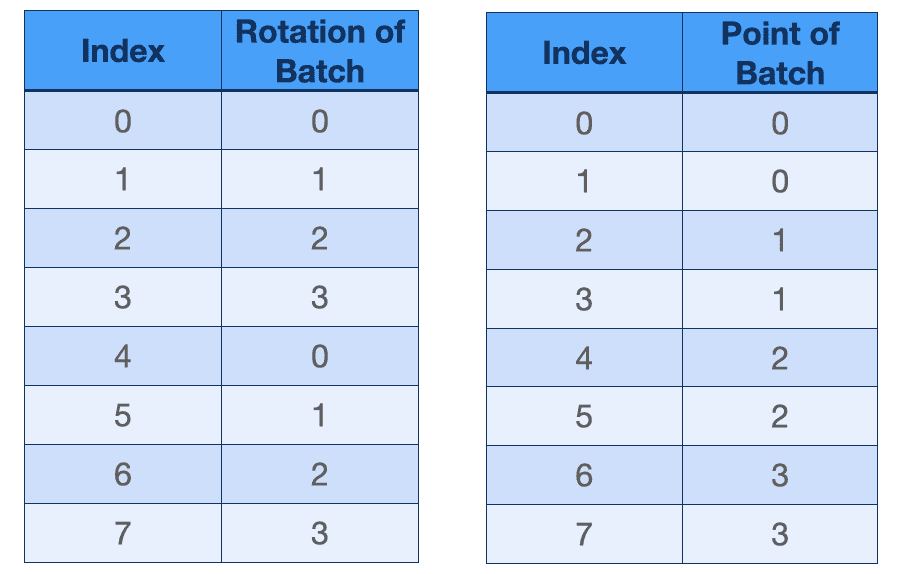
可能的解决方案
使用这样的方法,将 rotations 和 translations 先在各自的 batch 内部 tile,然后再像对 points 那样大瓶。有趣的是,这相当于先把 rotations 和 translations 调整成前两维与 points 相同的形状,然后和 points 一起 flatten。
1 | shape = points.shape |